Digital Phenotyping
The last decade has seen rapid advancements in the availability of mobile technology. As of today, approximately 4.8 billion people own a smartphone, and this number is predicted to increase to 6 billion by 2027 (Degenhard, 2024). The widespread use of mobile devices has led to a similar proliferation of mobile health (mHealth) research, including a plethora of implementations in psychiatric contexts (Rowland et al., 2020). These innovations offer promising new pathways in the treatment of mental disorders, where digital therapeutics are at the forefront of this new innovation cycle (Ebert et al., 2018). Digital psychological interventions allow to collect an unprecedented volume of fine-grained patient and process data. This may help to better identify behavioral markers of mental disorders, and to provide “just-in-time” adaptive interventions (JITAI) to patients when they need it the most (Harrer, Terhorst, et al., 2023).
A particularly promising innovation in this field is digital phenotyping, also known as “personal sensing” (Mohr et al., 2017), “mobile sensing” (Baumeister & Montag, 2023) or “reality mining” (Eagle & Pentland, 2006). In this approach, data from smartphones and other personal digital devices are used to quantify individuals' behaviors (i.e., the “phenotype”) in their natural environment. Optimally, this allows to derive digital markers (“digitomics”) that can be used to predict behavior, cognition, and mood (Baumeister & Montag, 2023; Torous et al., 2019). This technique may be particularly valuable within psychological interventions, which often resemble a “black box” (Collins, 2018, p. viii). In particular, phenotyping may help to improve our understanding of how symptoms develop within psychological interventions, address heterogeneity in patients' symptom trajectories, and predict high-risk situations for symptom deterioration.
Some of the potentials of digital phenotyping were explored in Article 5 (“Personalized Depression Forecasting”), in which we used sensor, voice and ecological momentary assessment (EMA) data to predict depressive symptom severity within a digital depression intervention. Forecasts were derived from data collected as part of the “mobile-based everyday therapy assistant with interaction-focused artificial intelligence” (MAIKI) trial. As part of this trial, patients with clinically relevant levels of depression (CES-D ≥ 16; n=65) who received treatment using a commercially available digital therapeutic (“HelloBetter Depression Prävention”) were additionally provided with an app-based symptom diary, the “HelloBetter MAIKI” application. This software was developed specifically for the trial to obtain intraday EMA ratings, “end-of-day” questionnaires and voice recordings, and was supplemented by the “Insights” framework to allow for passive sensing (including GPS-based movement patterns, communication behavior and phone usage; Montag et al., 2019). Wireframes of the “HelloBetter MAIKI” application are shown in Figure 12.
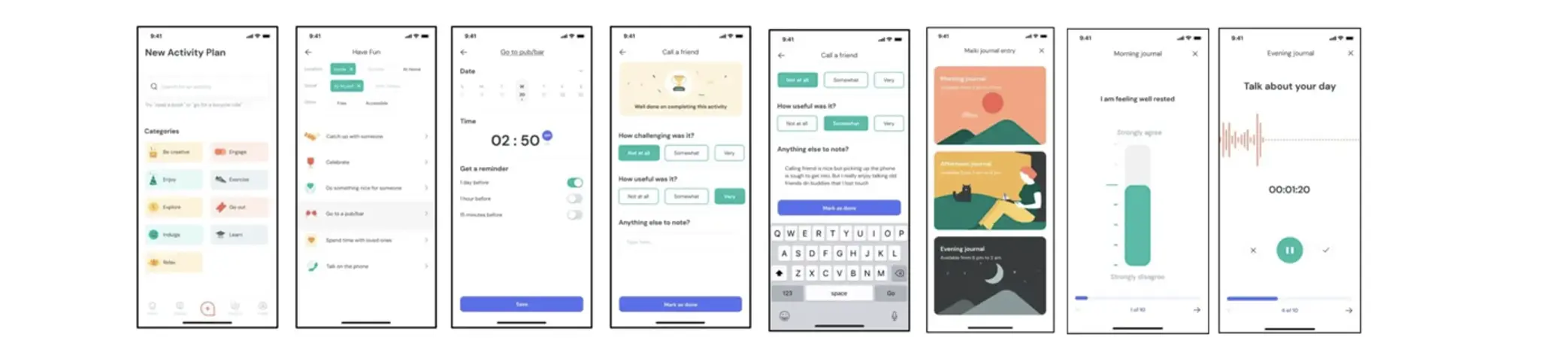
Using this technical setup, both active EMA and passive sensor data were obtained from patients for a period of eight weeks, the intended length of the digital depression intervention. As part of the digital phenotyping pipeline (see Figure 13 for a schematic illustration), a total of 19 features were derived from the collected passive sensor and system data; as well as seven psychometric indicators, which were established based on the provided EMA data (positive affect, negative affect, agentic/communal reward, workload, depressive symptoms, sleep quality, behavioral activation). As “ground truth”, we also measured patients' depressive symptom severity at the end of each day, operationalized by the PHQ-2 depression inventory, as well as symptoms over the last week, as measured by the PHQ-9. As part of the weekly screenings, patients also indicated their generalized anxiety (GAD-7) and levels of perceived stress (PSS-10).

In the study, we investigated whether sensor and EMA-based features derived from the MAIKI trial could predict depressive symptom severity while patients were undergoing treatment with a digital intervention. This target outcome was deemed clinically significant because accurate depression forecasts, even one or several days in advance, would enable anticipation of “sudden losses” and other rapid symptom changes during treatment. Identifying these changes early would be enormously helpful to administer therapeutic assistance exactly when it is needed; either through in-person support, or by triggering tailored content within the application. Deep learning architectures were used to generate the forecasts, whereby recurrent neural network (RNN) with gated recurrent units (GRUs) served as a baseline model (Cho et al., 2014).
One specific innovation in this study was to explore if the baseline GRU-RNN architecture could be improved using model personalization. Assuming that “depression” is a highly heterogenous construct, we hypothesized that adding further personalization layers while retaining a common backbone model would allow to enhance predictions, by allowing to “attune” the model to personal symptom dynamics within a designated “burn-in” phase. The most auspicious of the examined approaches was transfer learning with shared common layers, a method that has yielded promising results in previous mental health-related applications as well (see, e.g., Taylor et al., 2020). A schematic illustration of this approach is provided in Figure 14 below.
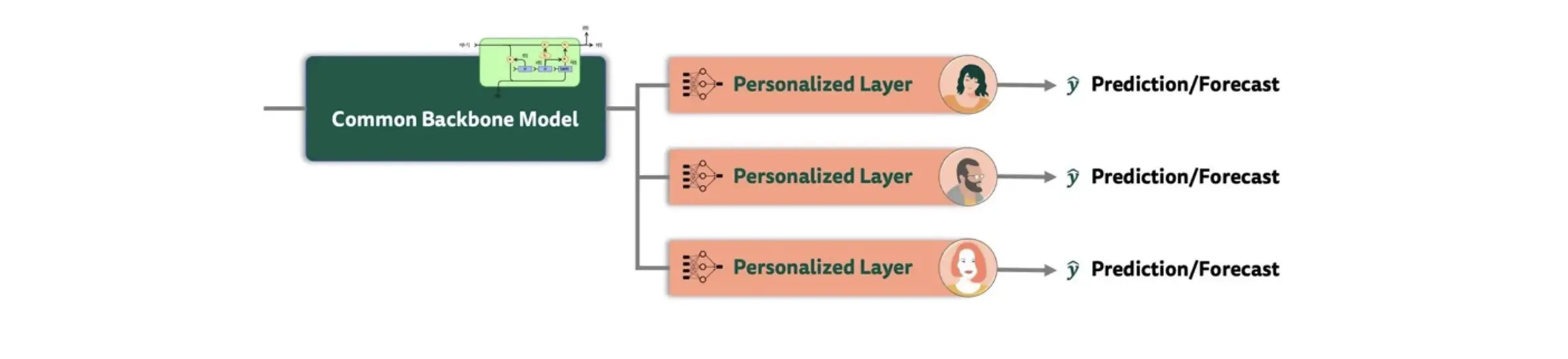
In transfer learning, common “population-level” layers are combined with personalized layers for each patient. At first, a baseline model was trained on all individuals, with two layers of the pretrained GRU-RNN serving as the backbone. To personalize the architecture, a fully-connected layer with 30 neurons was then added along with the output layer of the baseline model, which was fine-tuned separately to each patient, resulting in a unique model for each individual. This approach thus captures both general patterns across all patients, as well as more “idiosyncratic” information that may arise due to inherent heterogeneity in patients' symptomatology, as well as their individual response to treatment.